







 이미지 확대보기
이미지 확대보기네이버 AI의 ‘눈’, 중국 부품 논란
 이미지 확대보기
이미지 확대보기여기서 핵심은 부품 구조 복사 수준이 아니라, 수많은 사진을 보며 익힌 기억(가중치)을 함께 가져왔느냐 여부다. 가중치를 가져왔다는 것은, AI가 사진을 보고 “이것은 고양이야”라고 판단하는 기준을 중국 AI가 미리 만들어 놓은 것을 그대로 가져왔다는 의미다. 때문에 네이버가 처음부터 만든 AI라고 보기는 어렵다는 지적이다.
네이버 측은 “비전 인코더(사진 보는 눈)는 전 세계 표준화된 부품일 뿐, 핵심 두뇌(글 읽는 뇌)는 100% 네이버 기술”이라며 효율을 높인 전략적 선택이라고 강조하고 있다. VUClip 등 자체 사진 기술이 있지만 글로벌 호환성과 속도를 위해 내린 결정이라는 것이다.
하지만 업계는 여전히 “중국 AI가 어떠한 사진으로 학습하며 가중치를 쌓아왔는지 모르는데, 그 기억을 국가 프로젝트에 쓰는 것은 ‘한국형 AI’가 아니다”라는 입장이다.
네이버 맞춤 테스트 논란
이러한 사실이 알려지면서 정부 평가 기준도 논란이 됐다. 정부는 이번 프로젝트에서 5개 정예팀의 AI를 공통 테스트(LLM 표준 시험)로 비교하려고 했지만 문제가 생겼다. 다른 팀은 텍스트 중심의 AI를 내놓았는데, 네이버는 사진·영상·소리까지 보는 ‘옴니모달(다재다능한 AI) 모델’을 내놨기 때문이다.
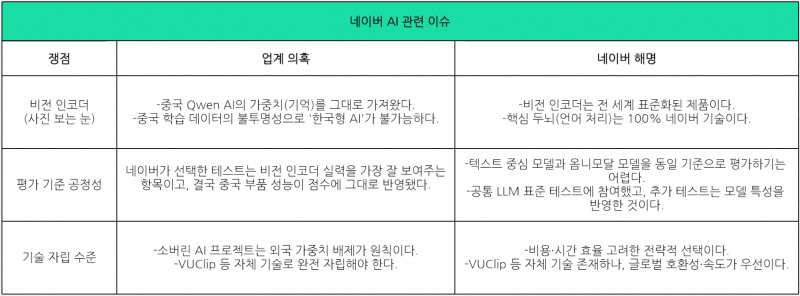
문제는 이 테스트들이 네이버 AI의 ‘사진 보는 눈’ 실력을 가장 잘 보여주는 항목이라는 점이다. 결과적으로 중국 부품 성능이 그대로 네이버 점수에 반영되는 꼴이 된 셈이다. 이에 텍스트와 사진을 동일 선상에 두고 평가하는 것은 불공정하다는 지적도 뒤따른다.
네이버의 딜레마 ‘효율 vs 자립’
 이미지 확대보기
이미지 확대보기하지만 정부 프로젝트는 ‘국가대표 AI’를 선발하는 자리인 만큼, 기준과 성격이 민간 시장과는 구분된다는 지적이 나온다. 이 프로젝트 취지는 ‘외국 기억 없이 한국 데이터로만 배우게 만드는 것’이 목표다. 즉, 가중치 주권이 핵심인 상황에서 네이버는 빠른 성능을 위한 부품 활용과, 국가 프로젝트를 위한 완전 자립 사이에서 딜레마에 빠진 것이다.
업계에서는 네이버가 글로벌 AI 생태계를 잡고 규제와 충돌하지 않기 위해서는 가중치(기억)를 새로 학습해야 한다는 내용으로 의견이 모아지고 있다. 자체 사진 기술을 더 키우고, 썼던 부품의 기억을 지운 증거를 보여 투명성을 입증해야 한다는 주장이다.
나아가 VUClip 기술로 ‘네이버만의 사진 보는 눈’을 속도전으로 개발해 자립도를 보여줘야 한다는 평가다. 전 세계 AI 회사들이 오픈소스 부품을 섞어 쓰는 현실에서 100% 처음부터 만들기는 비용과 시간 면에서 비효율적이지만, 정부가 지원하는 한국형 AI인 만큼 외국 기술 의존을 최소화하자는 취지다.
한편 이날 정부의 독자 AI 파운데이션 모델 개발 프로젝트 1차 평가 결과가 발표될 예정이다. 이번 평가 결과는 네이버뿐만 아니라 국내 AI 기업들의 개발 전략과 정부 지원 방향을 다시 점검하는 계기가 될 전망이다.
업계 관계자는 “이번 논란은 단순히 네이버 한 기업의 문제가 아니라, 한국이 어떤 AI 철학으로 갈지를 묻는 질문”이라며 “속도 경쟁 속에서도 기술 자립의 증거를 쌓는 노력이 결국 신뢰로 이어질 것”이라고 말했다.
정채윤 한국금융신문 기자 chaeyun@fntimes.com
[관련기사]
가장 핫한 경제 소식! 한국금융신문의 ‘추천뉴스’를 받아보세요~
데일리 금융경제뉴스 Copyright ⓒ 한국금융신문 & FNTIMES.com
저작권법에 의거 상업적 목적의 무단 전재, 복사, 배포 금지


![[DQN] ‘김동선 체제 4년’ 한화갤러리아, 사업확장 했지만 돈은 못 벌었다 [Z스코어 기업가치 바로보기]](https://cfnimage.commutil.kr/phpwas/restmb_setimgmake.php?pp=006&w=284&h=214&m=5&simg=2026030120193900218dd55077bc212411124362.jpg&nmt=18)
![박인원의 ‘휴머노이드 선언’...두산 ‘3차 대변신’ 이끌까 [K-휴머노이드 대전] ③ ‘오너 4세’ 주도 두산로보틱스](https://cfnimage.commutil.kr/phpwas/restmb_setimgmake.php?pp=006&w=284&h=214&m=5&simg=2026030120284507035dd55077bc212411124362.jpg&nmt=18)
![이재용 회장 ‘삼성의 미래ʼ PICK “올해 일 낸다” [K-휴머노이드 대전] ② 휴머노이드 원조 레인보우로보틱스](https://cfnimage.commutil.kr/phpwas/restmb_setimgmake.php?pp=006&w=284&h=214&m=5&simg=2026022214532407407dd55077bc221924192196.jpg&nmt=18)




![[인터뷰] 최인욱 두산에너빌리티 WPC 센터장 “두산이 하면 대한민국 최초, 그 자부심으로 일합니다”](https://cfnimage.commutil.kr/phpwas/restmb_setimgmake.php?pp=006&w=284&h=214&m=5&simg=20260303085809018500d260cda7512411124362.jpg&nmt=18)
![[DQN] ‘김동선 체제 4년’ 한화갤러리아, 사업확장 했지만 돈은 못 벌었다 [Z스코어 기업가치 바로보기]](https://cfnimage.commutil.kr/phpwas/restmb_setimgmake.php?pp=006&w=110&h=79&m=5&simg=2026030120193900218dd55077bc212411124362.jpg&nmt=18)
![박인원의 ‘휴머노이드 선언’...두산 ‘3차 대변신’ 이끌까 [K-휴머노이드 대전] ③ ‘오너 4세’ 주도 두산로보틱스](https://cfnimage.commutil.kr/phpwas/restmb_setimgmake.php?pp=006&w=110&h=79&m=5&simg=2026030120284507035dd55077bc212411124362.jpg&nmt=18)

![[인터뷰] 최인욱 두산에너빌리티 WPC 센터장 “두산이 하면 대한민국 최초, 그 자부심으로 일합니다”](https://cfnimage.commutil.kr/phpwas/restmb_setimgmake.php?pp=006&w=110&h=79&m=5&simg=20260303085809018500d260cda7512411124362.jpg&nmt=18)
![전국 해상풍력발전 24시간 모니터링…AI로 고장 예측 [두산에너빌 제주 WPC 가보니]](https://cfnimage.commutil.kr/phpwas/restmb_setimgmake.php?pp=006&w=110&h=79&m=5&simg=2026030120373904050dd55077bc212411124362.jpg&nmt=18)
{kind=link}
{kind=link}
{kind=link}
{kind=link}